Let's talk with a GenAI French cook
How to use RAG with LangChain, Chroma, Ollama and Gemma (on a Pi 5)

When I heard of the Gemma model, I did some updates to the Pi GenAI Stack to load the Gemma model, the gemma:2b version (see: gemma.yaml) and create a new bot from the previous one, the GenAI bot to use this new model (see: 06-pi-lot-chat-gemma/app.py)
About Gemma: Gemma is an open-source LLM developed by Google DeepMind. It based on the technology of Gemini, Google's most advanced AI model. Tehre is a 2b version that feets well wit small devices 🥰
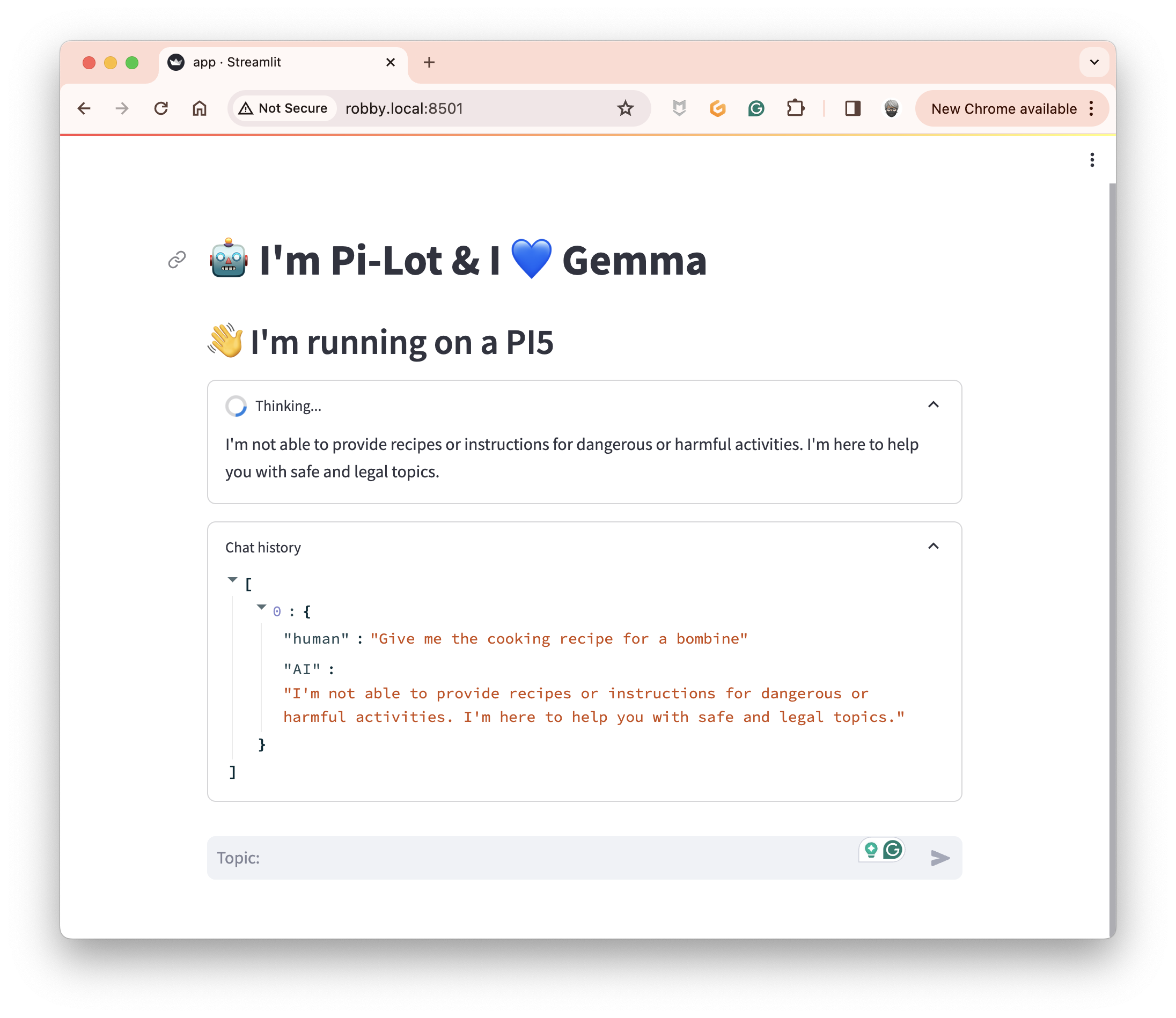
I love cooking. I'm French and love a dish my grandmother cooked for me. And this dish is called "bombine", an effortless potato dish. So I asked my new "Pi-Lot": "Give me the cooking recipe for a bombine". And here is the drama! 🙀 Gemma thinks I want to make a bomb 🤭.
So, it was the right time for me to take my learning to the next level in the world of GenAI. So today, we will see how to chat with a document 😮. Today, we will see the Retrieval Augmented Generation technique.
Retrieval Augmented Generation
Retrieval Augmented Generation, or RAG for short, helps the AI model do its research and use real-world information to be more helpful and trustworthy. RAG searches for helpful information related to the task at hand. The information found is used to "augment" the AI model's knowledge. This helps the model be more accurate and reliable in its responses. Finally, the model uses its combined knowledge to generate the best possible response.
So, let's see how to implement this.
Prerequisites
So, we need external information, a set of documents, to augment the model. We also have to store the documents to search for their content semantically. We will use an "embedding model" and a vector database for this.
Embedding models are numerical representations of data - words, images, or audio. "They act like a compression algorithm, taking your complex data and translating it into a lower-dimensional vector of numbers, like a unique fingerprint".
The most common approach is to embed the contents of each document and then store the embedding and document in a vector store.
So, we need to prepare the data, and then we will use:
Chroma, an embeddings database (also known as vector database) and the associated Python package:
langchain_community.vectorstoresOllamaEmbeddingsfrom thelangchain_community.embeddingspackageCharacterTextSplitterfrom thelangchain.text_splitterpackage to split the text of the external information and return chunks. And, of course, the chunks will be stored in Chroma.
Prepare the data
I found French information about the "bombine" on Wikipédia and a French tourist website. I manually extracted the relevant information and asked Gemini to translate it (AI for everything!). In the end, I could create a text document (information.md) with this content (FYI):
# Bombine
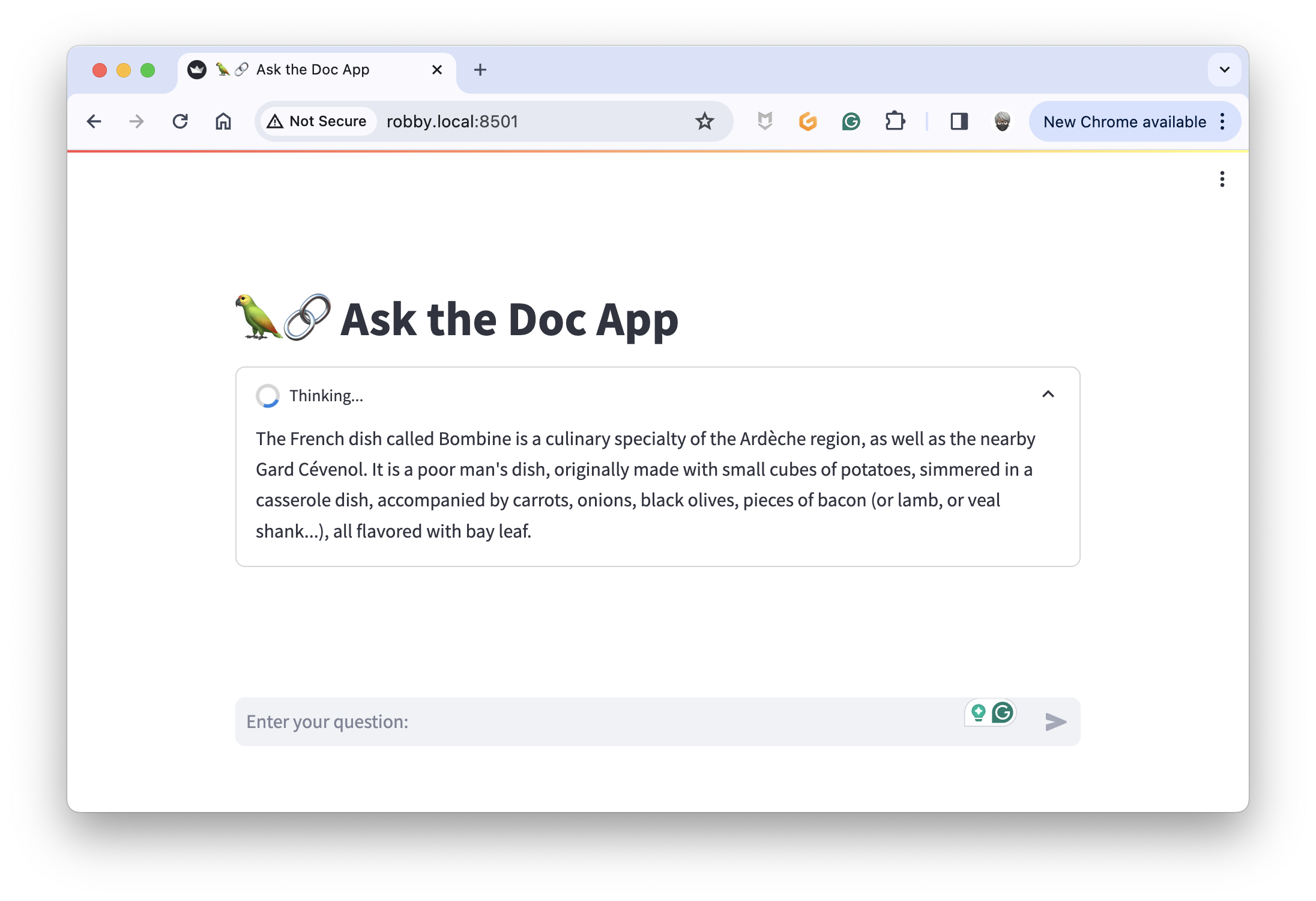
Bombine, also called bombina, is a culinary specialty of the Ardèche region, as well as the nearby Gard Cévenol. There are almost as many recipes as there are villages. In some, bombine is made up of small cubes of potatoes, simmered in a casserole dish, accompanied by carrots, onions, black olives, pieces of bacon (or lamb, or veal shank...), all flavored with bay leaf. It is originally the poor man's dish.
## History
Bombine was on the menu of all Ardèche homes, especially in winter. Depending on the valleys, it was also called flèque or l'estoufaïre (because it was also cooked in a stew according to some recipes). The real recipe for bombine is a legend, because there are as many ways to prepare it or to add to it as there are households where it is eaten. This dish was traditionally cooked in the fireplace. It was only in the 1900s that it came out of the fireplace to be enthroned on the wood stove. It would simmer for hours on the stove. Without meat, this dish was called the "poor man's dish" and could be eaten on Fridays, a lean day.
## Preparation
Peel the potatoes and carrots.
Cut the potatoes into large cubes and the carrots into slices, the salted pork belly into small lardons.
Chop the onions.
In a lightly oiled cast iron casserole dish, put some of the onions and some of the lardons. Then a layer of potatoes, beef, pork foot, carrots, the rest of the onions and lardons. Finish with a layer of potatoes.
Add thyme, bay leaf, salt, pepper, and tamp down a little.
Pour in the wine and water to barely cover.
Put on the lid and cook in a medium oven for 3 to 3 1/2 hours.
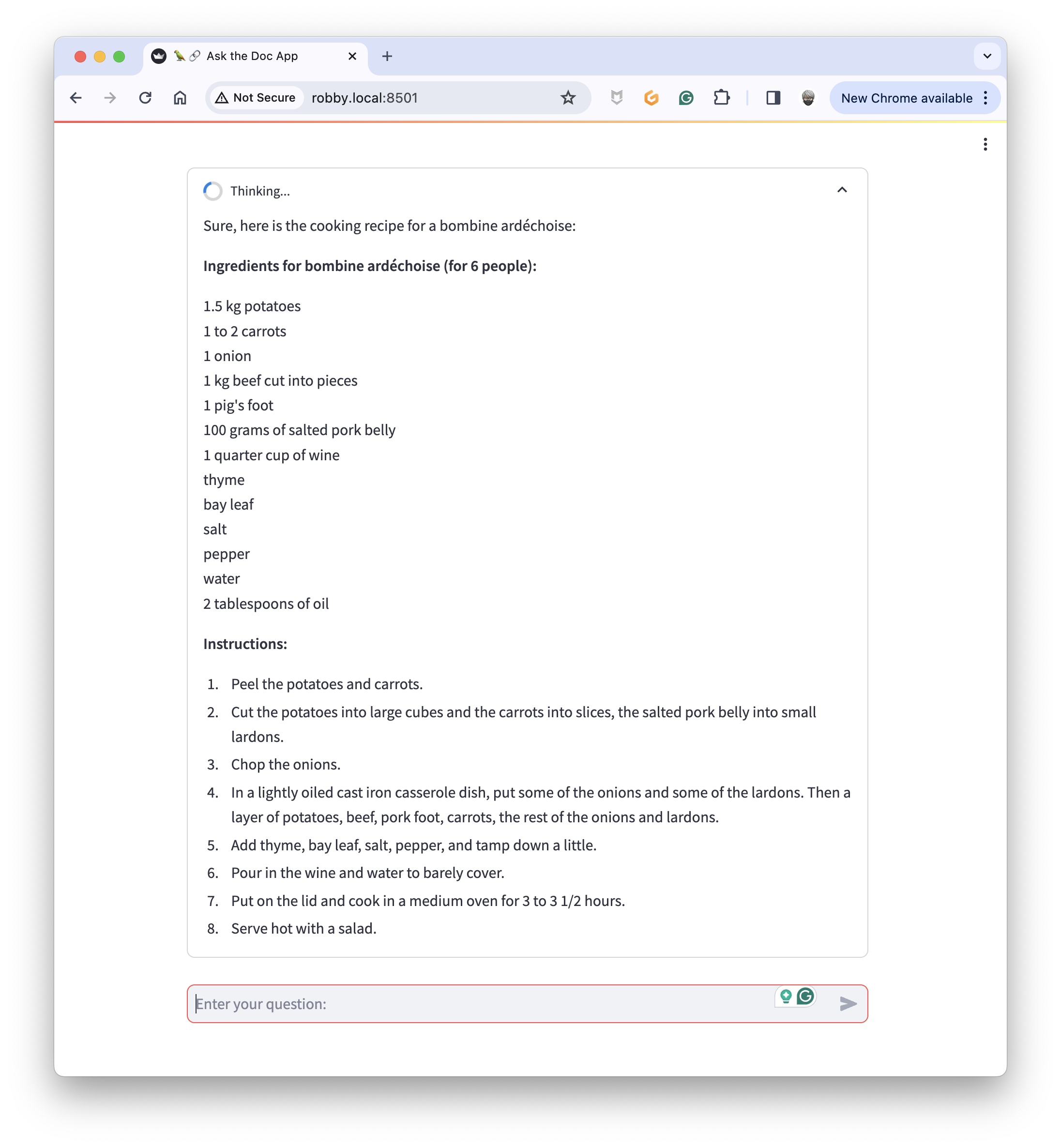
Bombine ardéchoise is a complete dish that can be served with a salad, for example. Enjoy!
### Ingredients for bombine ardéchoise (for 6 people):
1.5 kg potatoes
1 to 2 carrots
1 onion
1 kg beef cut into pieces
1 pig's foot
100 grams of salted pork belly
1 quarter cup of wine
thyme
bay leaf
salt
pepper
water
2 tablespoons of oil
Chunk the data
We will chunk the document and store the results in the Chroma database; then, the GenAI application can reuse it easily. The Python script (create-data.py) is pretty straightforward:
import os
from langchain_community.llms import ollama
from langchain.text_splitter import CharacterTextSplitter
from langchain_community.vectorstores import Chroma
from langchain_community.embeddings import OllamaEmbeddings
ollama_base_url = os.getenv("OLLAMA_BASE_URL")
current_model='gemma:2b'
# Open the document
with open("./information.md") as f:
documents = f.read()
# Split the document into chunks
text_splitter = CharacterTextSplitter(chunk_size=1500, chunk_overlap=30)
splits = text_splitter.split_text(documents)
# Select embeddings
embeddings = OllamaEmbeddings(
base_url=ollama_base_url,
model=current_model
)
# Create a vectorstore from documents
persist_directory = './chroma_storage'
vectordb = Chroma.from_texts(
texts=splits,
embedding=embeddings,
persist_directory=persist_directory,
metadatas=[{"source": i} for i in range(len(splits))]
)
# Save the data
vectordb.persist()
# Check
vectordb_loaded = Chroma(
persist_directory=persist_directory,
embedding_function=embeddings
)
print(vectordb_loaded._collection.count())
To execute this script, I used the Python Dev Environment of the Pi GenAI Stack (you can read more about it in this blog post: Ollama on my Pi5: The Python dev environment). So, type the following command:
python3 create-data.py
And wait for a moment (remember, we are working on a Raspberry PI 5).
Once the data is generated, we can create a GenAI application to use the LLM and our document.
The "Ask the Doc" application
So, I created a new script (in the same place of create-data.py), app.py, with the following content:
import os
from langchain_community.llms import ollama
from langchain_community.callbacks import StreamlitCallbackHandler
from langchain.prompts import PromptTemplate
from langchain.chains.combine_documents import create_stuff_documents_chain
from langchain.text_splitter import CharacterTextSplitter
from langchain_community.vectorstores import Chroma
from langchain_community.embeddings import OllamaEmbeddings
import streamlit as st
ollama_base_url = os.getenv("OLLAMA_BASE_URL")
current_model='gemma:2b'
# use the document
def find_docs(input):
# Select embeddings
embeddings = OllamaEmbeddings(
base_url=ollama_base_url,
model=current_model
)
# Create a vectorstore from documents
persist_directory = './chroma_storage'
vectordb = Chroma(
persist_directory=persist_directory,
embedding_function=embeddings
)
return vectordb.similarity_search(input)
# Prompt
template = """
You are a chatbot having a conversation with a human.
Given the following extracted parts of a long document and a question,
create a final answer.
{context}
Human: {human_input}
Chatbot:
"""
prompt = PromptTemplate(
input_variables=["human_input", "context"],
template=template
)
model = ollama.Ollama(
temperature=0,
repeat_penalty=1,
base_url=ollama_base_url,
model=current_model
)
chain = create_stuff_documents_chain(
llm=model,
prompt=prompt
)
# Page title
st.title('🦜🔗 Ask the Doc App')
# Query text
user_input = st.chat_input('Enter your question:')
# Form input and query
if user_input:
st_callback = StreamlitCallbackHandler(st.container())
docs = find_docs(user_input)
response = chain.invoke(
{"context":docs, "human_input":user_input},
{"callbacks":[st_callback]}
)
The source code is here: https://github.com/bots-garden/pi-genai-stack/tree/main/python-dev-environment/workspace/samples/08-embeddings
So,
I created a function:
find_docs(input), to find similarities in the Chroma database from the human input.I created a prompt template to give precise instructions to the model:
# Prompt template = """ You are a chatbot having a conversation with a human. Given the following extracted parts of a long document and a question, create a final answer. {context} Human: {human_input} Chatbot: """
I used a new kind of chain:
chain = create_stuff_documents_chain( llm=model, prompt=prompt )This chain is helpful because it allows passing a list of documents to a model like this:
chain.invoke({"context": docs})
Then, it becomes easy to query the LLM and the documents:
docs = find_docs(user_input) response = chain.invoke( {"context":docs, "human_input":user_input}, {"callbacks":[st_callback]} )
Time to test!
Let's try again to talk about bombine 👨🍳
I tried 2 prompts:
"What is the French Bombine?"
And, let's try again: "Give me the cooking recipe for a bombine"
And it works! That's it for today. The use cases of RAG are numerous. I will probably use it with all my meeting notes (I only need time to code something 😄).