Make a GenAI Conversational Chatbot with memory.
With Ollama, LangChain & StreamLit. And, again, it runs on my 🥰 Pi5.

With the example of my previous blog post, Make a GenAI Web app in less than 40 lines of code, we could ask a question about a particular programming language, but on the next question, the application had lost its memory. So, having "an ongoing conversation" with the application was impossible. The only possible "link" was the choice of language (which was re-injected into the prompt).
Today, we will create (from the previous code) a chatbot with memory.
How are we going to do this?
Again, I will use the Python dev environment of the Pi GenAI Stack, so there is no need to install anything. All dependencies are provided with the stack.
The Pi GenAI Stack is a Docker Compose project that runs Ollama with small models and provides a Python WEB IDE for experiments. (There is a JavaScript WEB IDE too, but I will write about it later)
We will use two things:
a
ConversationBufferMemorya
ConversationChain
The ConversationBufferMemory is a memory for storing messages and then extracting them to re-inject them into the prompt (allowing the conversation).
The ConversationChain is a chain to make a conversation; it loads the context from memory and calls the LLM. The ConversationChain uses the ConversationBufferMemory that remembers all previous inputs/outputs and adds them to the context passed to the LLM.
So, start the Pi GenAI Stack. Once the Web IDE is launched, create a directory (04-streamlit-memory), and add a new file (app.py) in this directory with the following code:
import os
from langchain_community.llms import ollama
from langchain_community.callbacks import StreamlitCallbackHandler
from langchain.prompts import PromptTemplate
# All we need for a good chat
from langchain.memory import ConversationBufferMemory
from langchain.chains import ConversationChain
import streamlit as st
ollama_base_url = os.getenv("OLLAMA_BASE_URL")
memory = ConversationBufferMemory()
## session state variable
if 'chat_history' not in st.session_state:
st.session_state.chat_history=[]
else:
for message in st.session_state.chat_history:
memory.save_context({'input': message['human']}, {'output': message['AI']})
prompt_template = PromptTemplate(
input_variables=['history', 'input'],
template="""
You are a friendly bot.
Conversation history:
{history}
Human: {input}
AI:
"""
)
model = ollama.Ollama(
temperature=0,
repeat_penalty=1,
base_url=ollama_base_url,
model='tinyllama',
)
conversation_chain = ConversationChain(
prompt=prompt_template,
llm=model,
memory=memory,
verbose=True, # then you can see the intermediate messages
)
# Add a title and a subtitle to the webapp
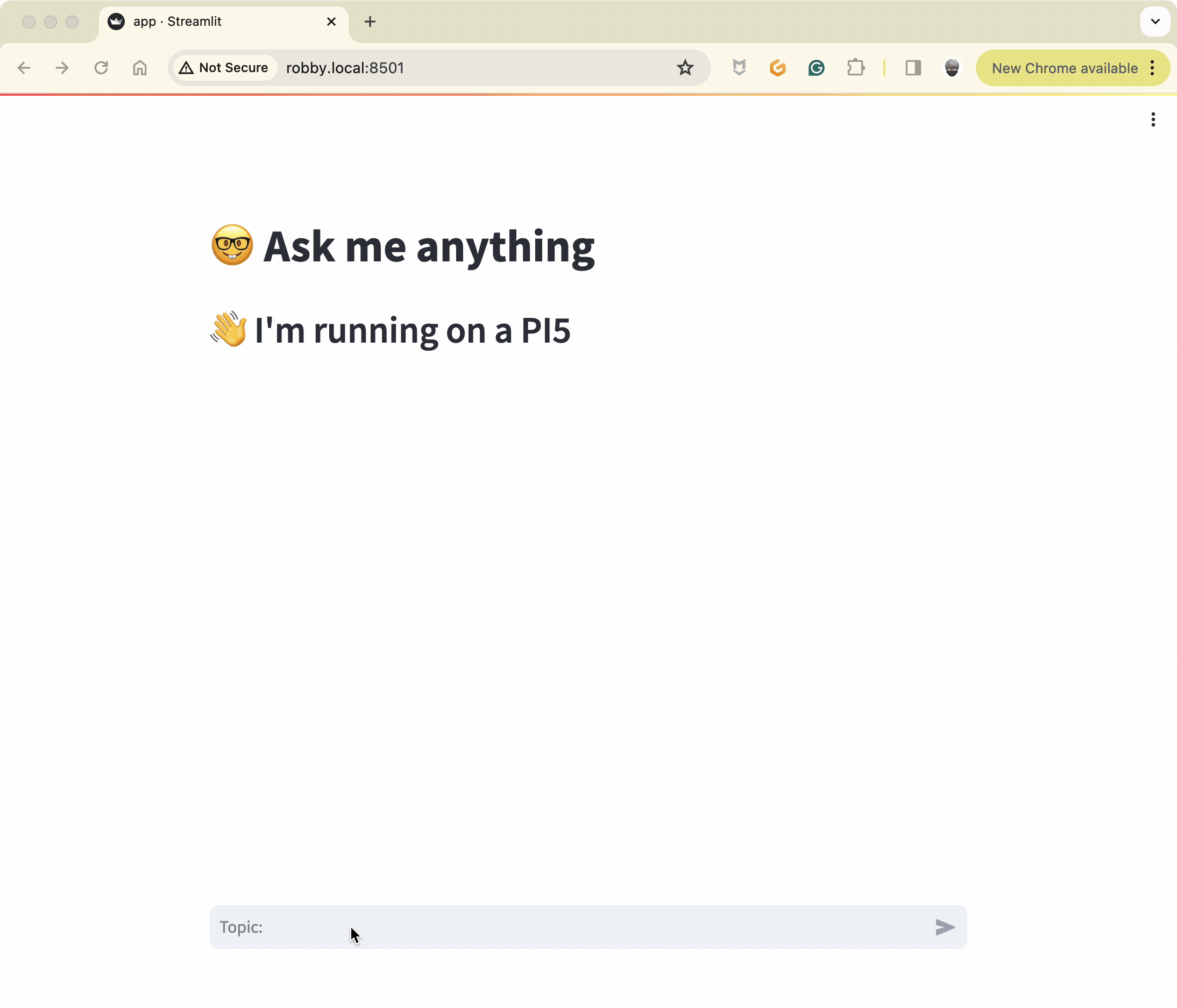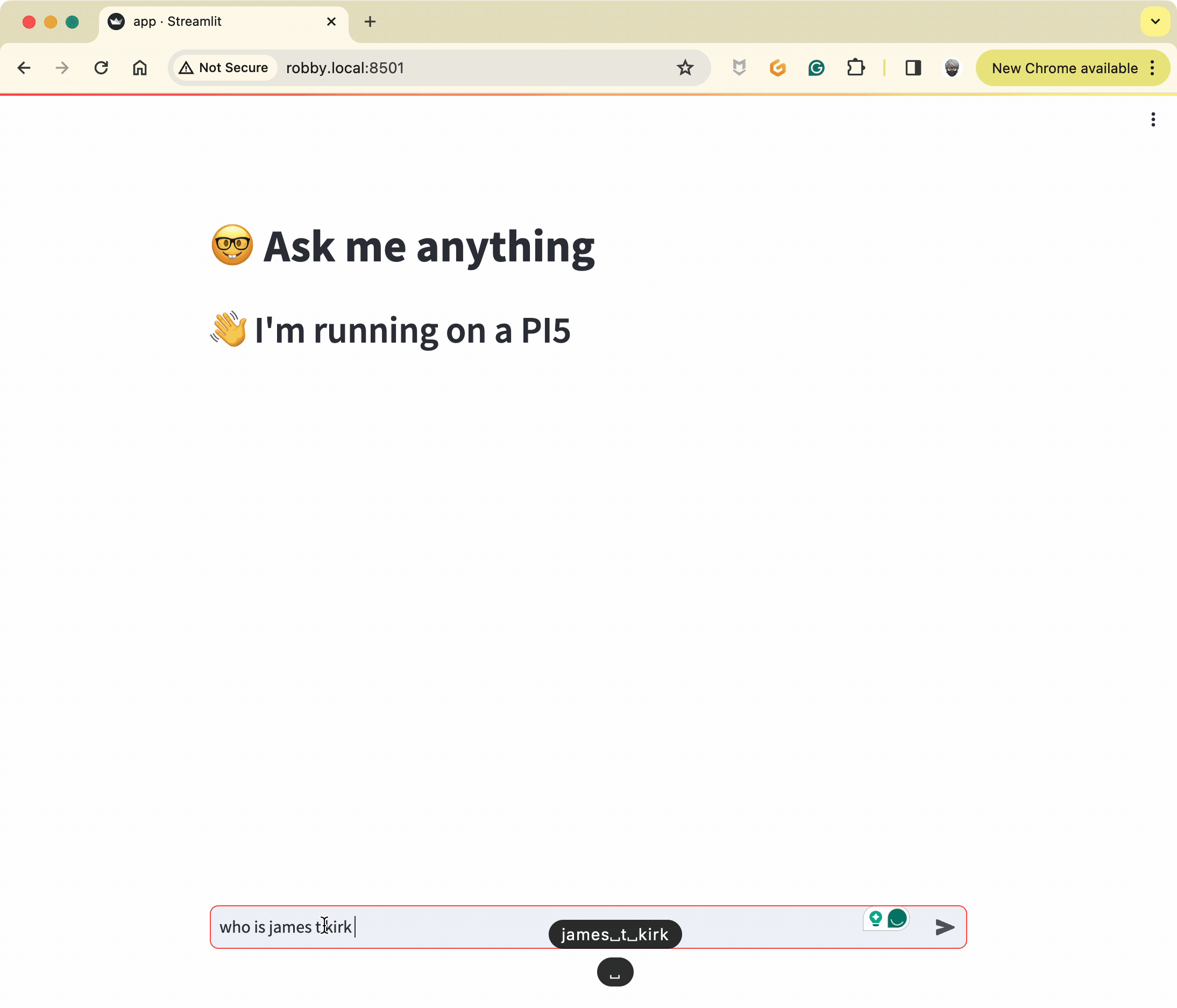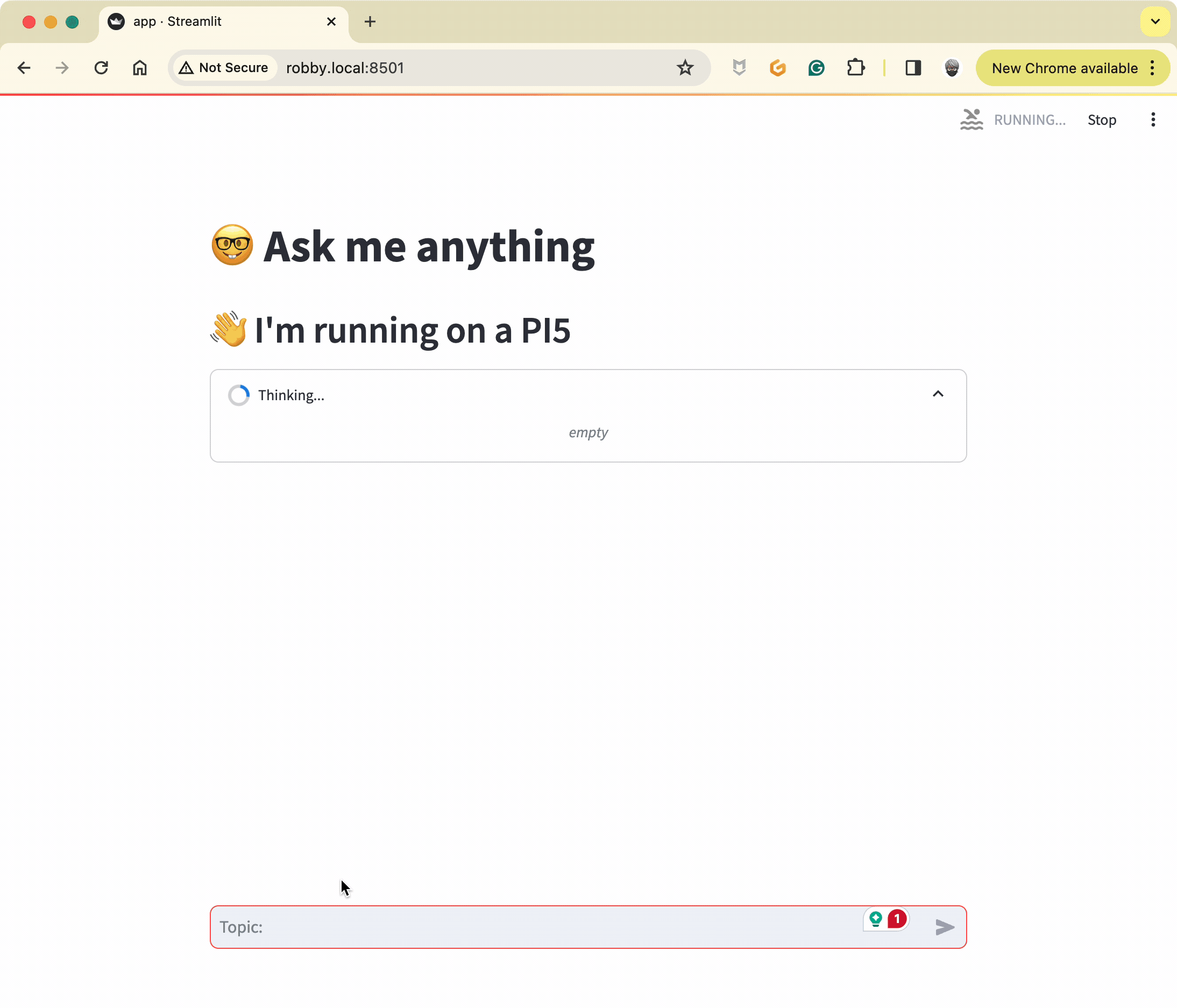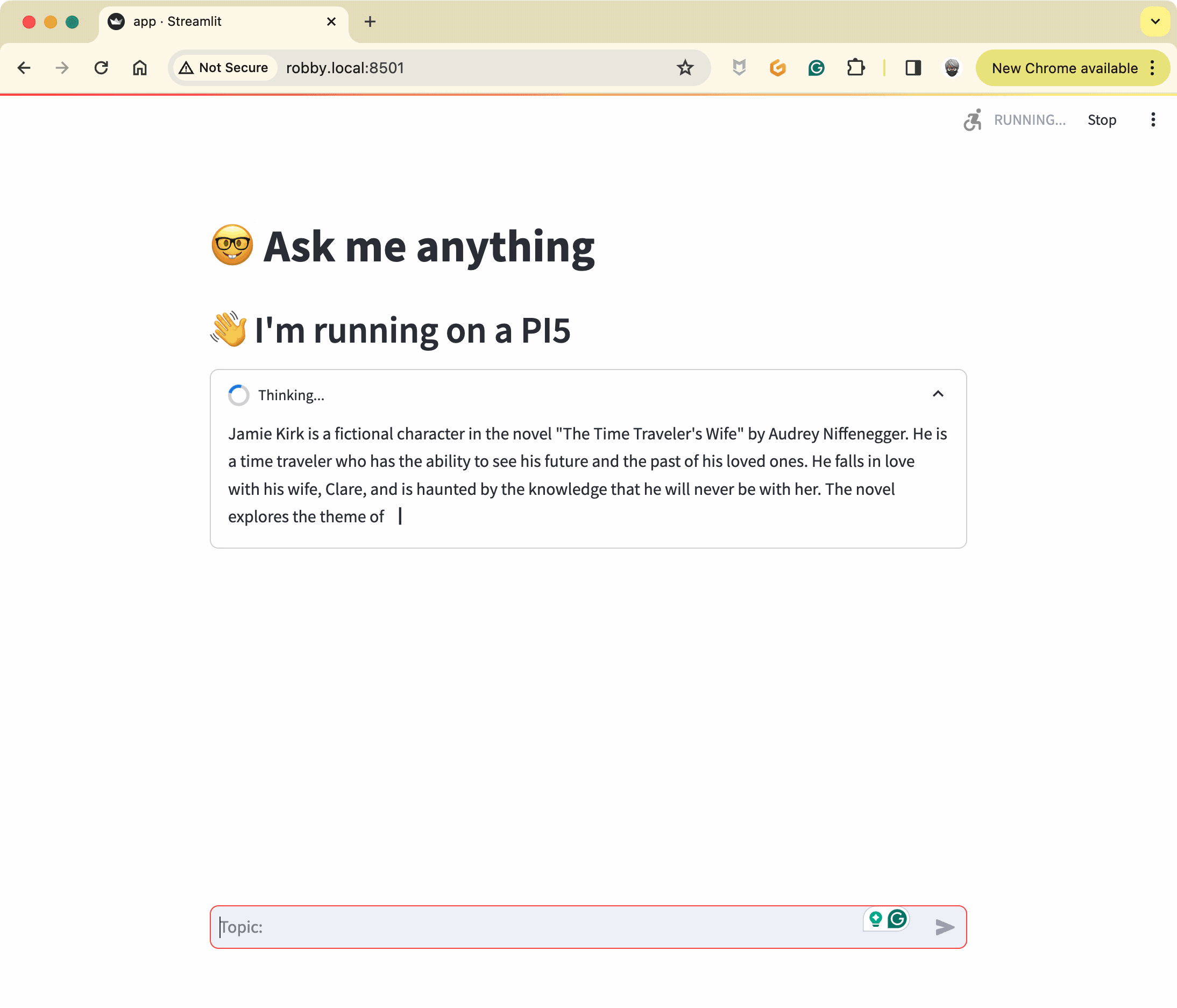
st.title("🤓 Ask me anything")
st.header("👋 I'm running on a PI5")
# Text input fields
user_input = st.chat_input("Topic:")
# Executing the chain when the user
# has entered a topic
if user_input:
st_callback = StreamlitCallbackHandler(st.container())
response = conversation_chain.run(input=user_input, history=st.session_state["chat_history"], callbacks=[st_callback])
message = {'human': user_input, 'AI': response}
st.session_state.chat_history.append(message)
with st.expander(label='Chat history', expanded=False):
st.write(st.session_state.chat_history)
Before running this code, here are some explanations:
Session State & Conversation Memory
I use a session state (st.session_state) to keep the data between every re-run, and I use it to feed the memory (memory = ConversationBufferMemory())
At the beginning, I load the state into the memory:
if 'chat_history' not in st.session_state:
st.session_state.chat_history=[]
else:
for message in st.session_state.chat_history:
memory.save_context({'input': message['human']}, {'output': message['AI']})
And at every answer of the bot, I store the question and the answer into the session state:
message = {'human': user_input, 'AI': response}
st.session_state.chat_history.append(message)
Temperature & Repetition Penalty
This time, when I create the model, I add a temperature:
model = ollama.Ollama(
temperature=0,
repeat_penalty=1,
base_url=ollama_base_url,
model='tinyllama',
)
The temperature parameter adjusts the randomness of the output. A higher temperature (0.7) for creative writing can spark unexpected ideas. For factual tasks, a lower temperature (0.2) ensures accuracy.
The repeat_penalty is a technique used with LLM during text generation to avoid repetitive output. According to the documentation of LangChain, 1 means no penalty, higher value = less repetition, and lower value = more repetition. But I feel you need to tune this for every model you use.
I let the temperature to 0 and the repetition penalty to 1 with the small models to avoid too much madness 🤪.
Prompt
The prompt is more complete than last time:
prompt_template = PromptTemplate(
input_variables=['history', 'input'],
template="""
You are a friendly bot.
Conversation history:
{history}
Human: {input}
AI:
"""
)
I use the {history} variable to re-inject the memory into the prompt.
Conversation Chain
This chain uses, as parameters, the prompt, the model and the conversation memory. verbose=True activates the logs.
conversation_chain = ConversationChain(
prompt=prompt_template,
llm=model,
memory=memory,
verbose=True, # then you can see the intermediate messages
)
Run the chain
To run the chain, I call the run method of the chain with user input and the history as parameters (callbacks=[st_callback] allows streaming the content to the page for a better user experience). And I update the session state.
if user_input:
st_callback = StreamlitCallbackHandler(st.container())
response = conversation_chain.run(input=user_input, history=st.session_state["chat_history"], callbacks=[st_callback])
message = {'human': user_input, 'AI': response}
st.session_state.chat_history.append(message)
These last lines allow you to display the history in a kind of combo box:
with st.expander(label='Chat history', expanded=False):
st.write(st.session_state.chat_history)
Start the ChatBot!
To run the application, use the below command:
streamlit run app.py
Now, open the web app with the following URL http://<ip address of your Pi>:8501 and start talking.
✋ Don't forget that is more job than usual for the Pi (the prompt is bigger and bigger), so the computation is slower (but still usable)
✋ Addendum to the "Run the chain" paragraph (update: 2024-02-22)
When you are running the demo, you probably saw this warning message:
/usr/local/lib/python3.11/site-packages/langchain_core/_api/deprecation.py:117: LangChainDeprecationWarning: The function run was deprecated in LangChain 0.1.0 and will be removed in 0.2.0. Use invoke instead.
Now, you should use this:
response = conversation_chain.invoke(
{"input":user_input, "history":st.session_state["chat_history"]},
{"callbacks":[st_callback]}
)
And 🔥 be careful, the structure of the response has changed. With the run method, the response was a simple string (raw text). Since then, the structure is the following: {input, history, response}. So, to save the state, use this:
message = {'human': user_input, 'AI': response["response"]}