Add memory to our GenAI application
With LangChainJS, Ollama and Fastify, still on a Pi 5 (and propelled by 🐳 Docker Compose)

In the previous blog post, "Create a Web UI to use the GenAI streaming API", we created a Web UI to use the GenAI API created in "GenAI streaming API with LangChainJS, Ollama and Fastify". Now, we have a usable GenAI Chatbot. Today, we will improve it by adding memory to it (him/her?).
Let me explain: If I ask the Chatbot to create a "hello world" program in Golang, and after the first generation, I ask the Chatbot to add a line to display "👋 hello people," the Chatbot will be lost and will probably recreate a program in another language (because the bot didn't keep the context of the previous question).
To have a "real" conversation, the solution is to keep the history of all the messages (questions and answers) and use this history to reinject the context into the prompt. Then, the bot's answer will be more accurate.
So, let's do it.
Add the memory management to the GenAI API
As usual, I continue to use the Pi GenAI stack to develop this example, but it's straightforward to transform it into a standalone project (it will be the topic of an incoming blog post).
Let's start with our previous project (look at "Create a Web UI to use the GenAI streaming API")
.
├── index.mjs
└── public
├── css
│ └── bulma.min.css
├── index.html
└── js
└── markdown-it.min.js
We only work on index.mjs (the GenAI API).
Here are the new objects of LangChainJS I will use to implement the memory of the Chatbot:
ChatMessageHistory: It allows you to store human messages (messages you send) easily and AI messages (messages you receive from a chatbot) and then access them later (Chat Message History documentation). The messages are saved in memory. For something more robust and persistent, there are several other ways to store the messages in databases: see Chat Memory documentation. And I used this handy example: Add message history (memory)RunnableWithMessageHistory: It allows the integration of the history into the LCEL chain. It creates a memory of past conversations and uses that information to inform future interactions with the LCEL chain. An LCEL (LangChain Expression Language) chain is a specific way to build sequences of tasks or actions within the LangChain framework. (RunnableWithMessageHistory documentation)MessagesPlaceholder: this object will add the history to the prompt (MessagePlaceholder documentation).
This is the updated source code of index.mjs:
import Fastify from 'fastify'
import path from 'path'
import fastifyStatic from '@fastify/static'
import { ChatOllama } from "@langchain/community/chat_models/ollama"
import { StringOutputParser } from "@langchain/core/output_parsers"
import { RunnableWithMessageHistory } from "@langchain/core/runnables" // 👋
import { ChatMessageHistory } from "langchain/stores/message/in_memory" // 👋
import {
SystemMessagePromptTemplate,
HumanMessagePromptTemplate,
MessagesPlaceholder,
ChatPromptTemplate
} from "@langchain/core/prompts"
let ollama_base_url = process.env.OLLAMA_BASE_URL
const model = new ChatOllama({
baseUrl: ollama_base_url,
model: "deepseek-coder",
temperature: 0,
repeatPenalty: 1,
verbose: true
})
const prompt = ChatPromptTemplate.fromMessages([
SystemMessagePromptTemplate.fromTemplate(
`You are an expert in computer programming.
Please make friendly answer for the noobs.
Add source code examples if you can.
`
),
new MessagesPlaceholder("history"), // 1️⃣ add a history section
HumanMessagePromptTemplate.fromTemplate(
`I need a clear explanation regarding my {question}.
And, please, be structured with bullet points.
`
)
])
// 2️⃣ initialize the chat memory
const messageHistory = new ChatMessageHistory()
const fastify = Fastify({
logger: true
})
// Serve public/index.html
fastify.register(fastifyStatic, {
root: path.join(import.meta.dirname, 'public'),
})
const { ADDRESS = '0.0.0.0', PORT = '8080' } = process.env;
fastify.post('/prompt', async (request, reply) => {
const question = request.body["question"]
const outputParser = new StringOutputParser()
const chain = prompt.pipe(model).pipe(outputParser)
// 3️⃣ create a RunnableWithMessageHistory object
// passing in the chain created before
const chainWithHistory = new RunnableWithMessageHistory({
runnable: chain,
getMessageHistory: (_sessionId) => messageHistory,
inputMessagesKey: "question",
historyMessagesKey: "history",
})
// 4️⃣ this object is used to identify the chat sessions
const config = { configurable: { sessionId: "1" } }
// 5️⃣ use the new chain to stream the answer
let stream = await chainWithHistory.stream({
question: question,
}, config)
reply.header('Content-Type', 'application/octet-stream')
return reply.send(stream)
})
const start = async () => {
try {
await fastify.listen({ host: ADDRESS, port: parseInt(PORT, 10) })
} catch (err) {
fastify.log.error(err)
process.exit(1)
}
console.log(`Server listening at ${ADDRESS}:${PORT}`)
}
start()
Some explanations:
Add a history section to the prompt.
Initialize the chat memory.
Create a
RunnableWithMessageHistoryobject passing in the chain created before. ThegetMessageHistorymethod is optional and can be used to track history by session ID, but in your case, it is useless because, for now, Ollama is designed to run on a local machine for a single user.The configurable object is used to identify the chat sessions.
Use the new chain
chainWithHistoryto stream the answer.
Let's have a real discussion
Into the directory of the application, type the following command to start the application:
node index.mjs
And reach the Web UI of the Chatbot. I started with a simple prompt to get some generated source code in Golang:
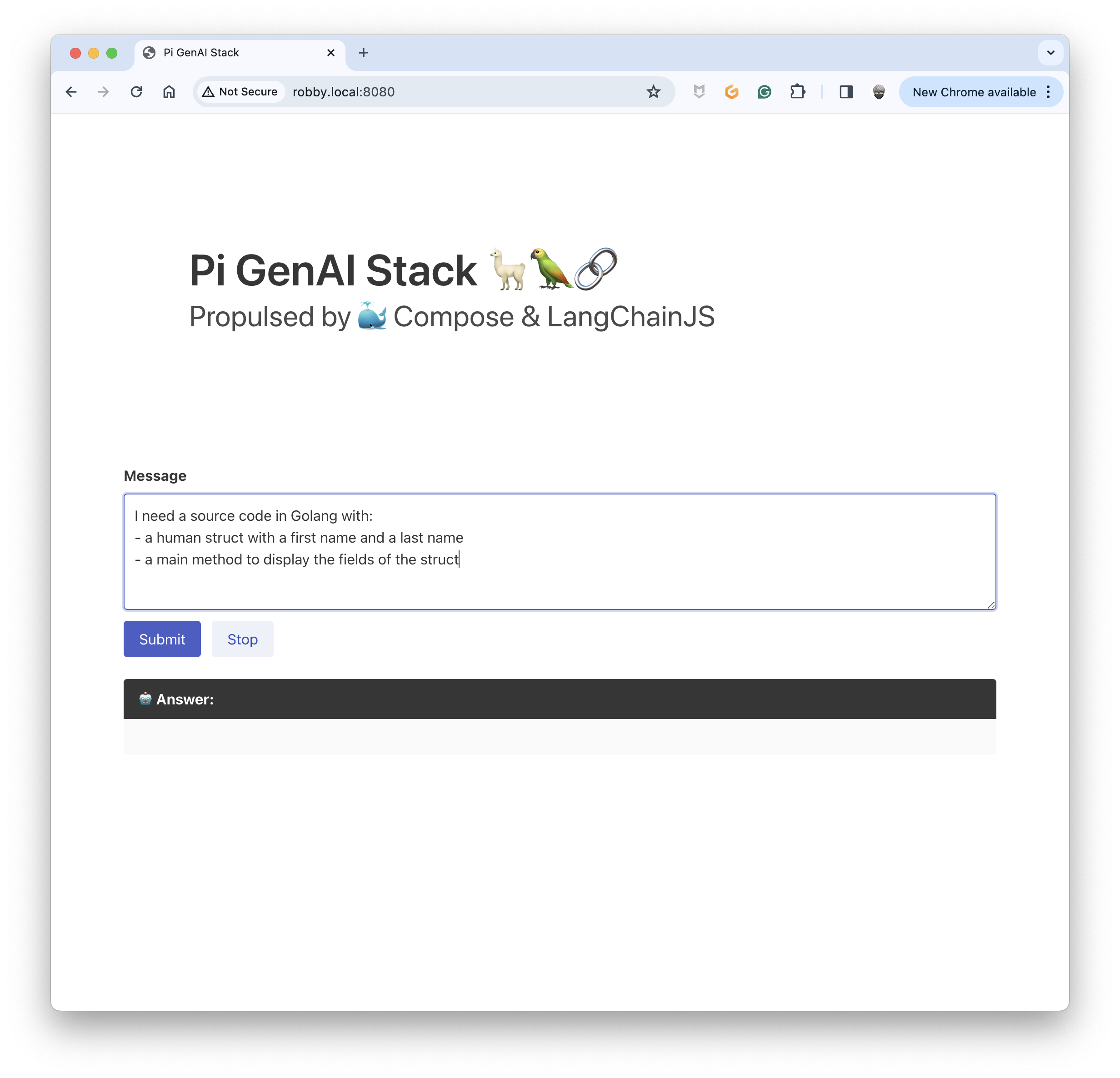
The answer is pretty accurate:
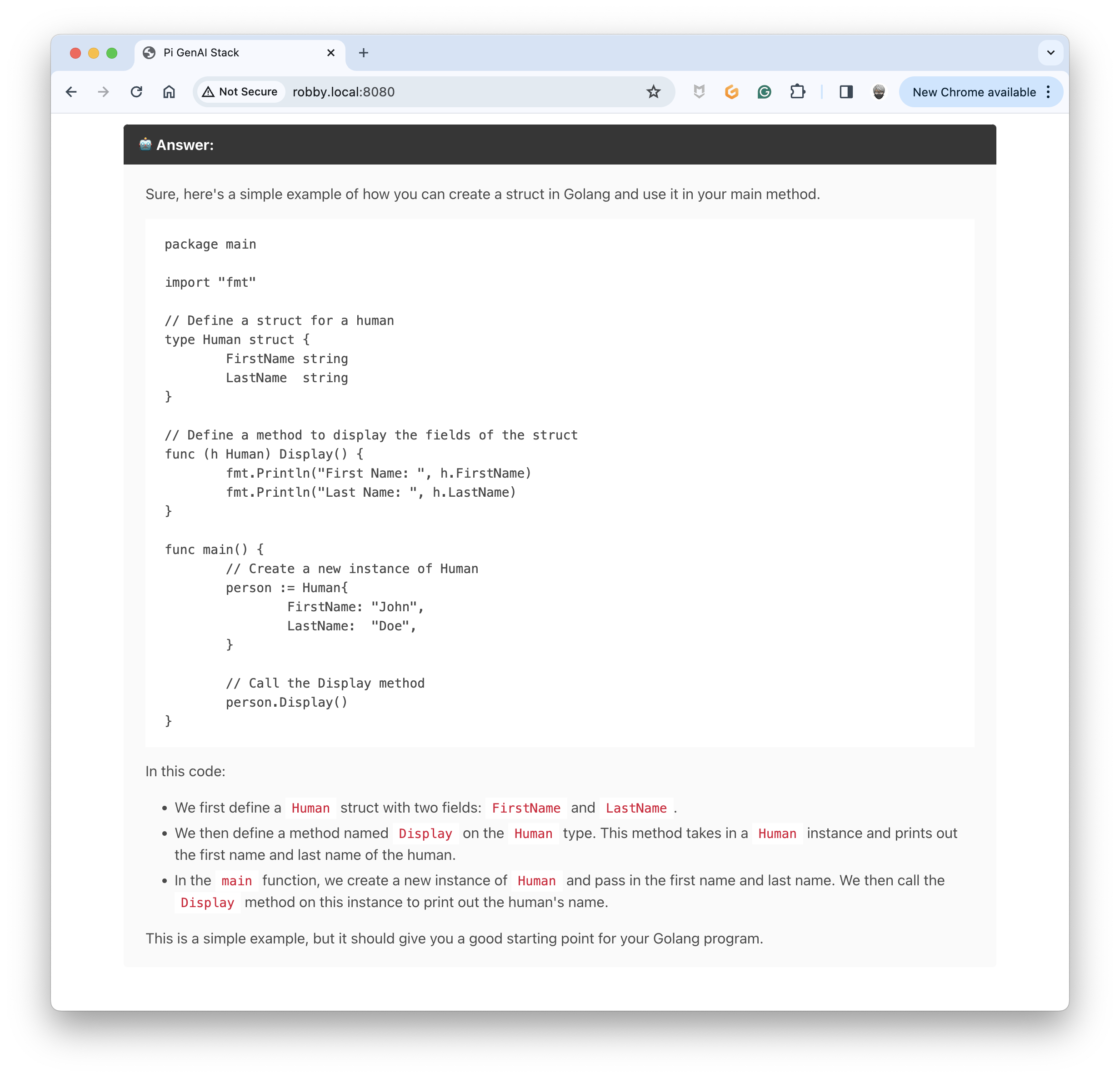
Now, I would add some updates to the source code (I don't specify that is in Golang, nor the name of the structure):
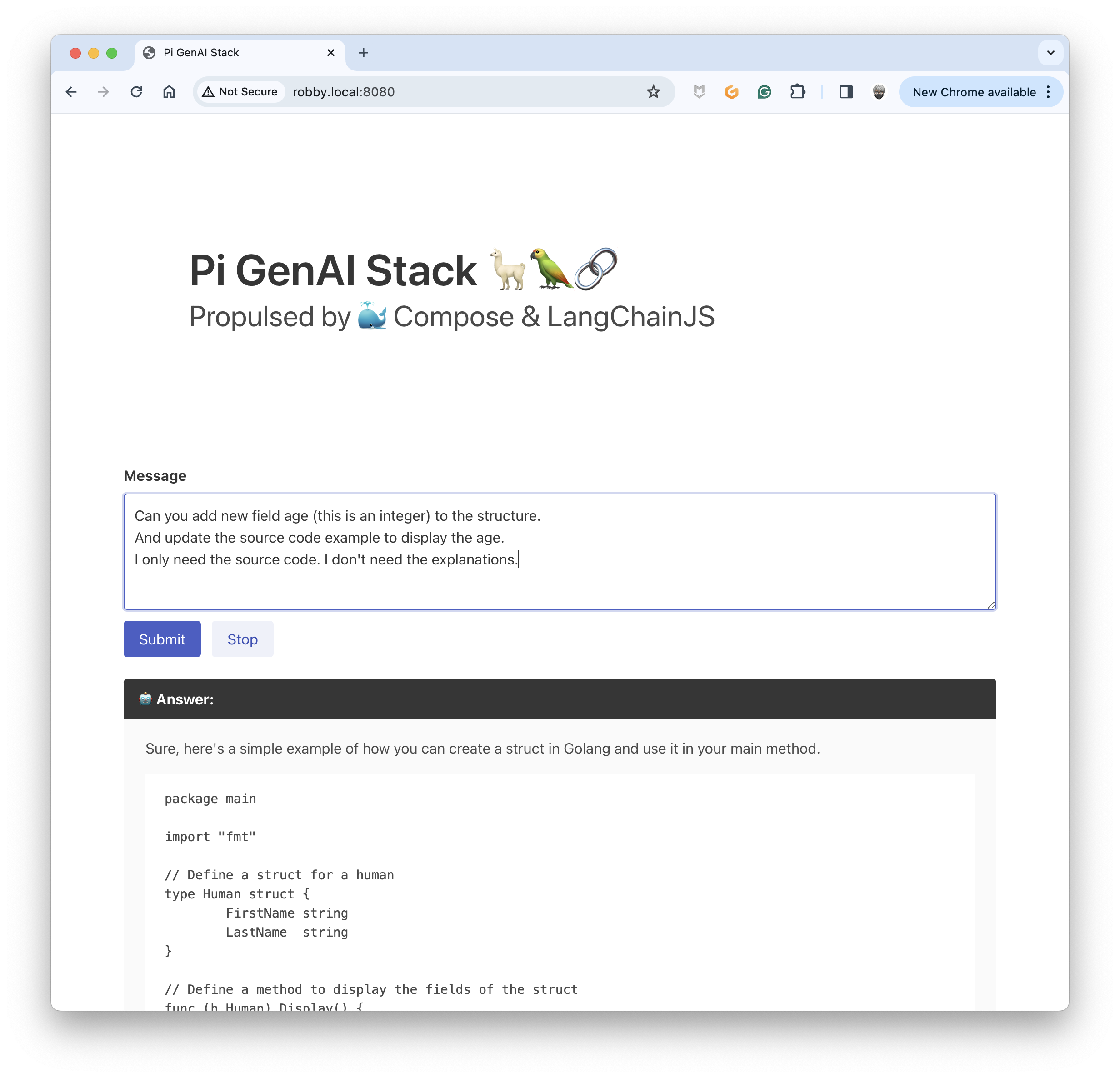
Wait for a moment (✋ with the usage of the memory, the delay of answering is longer than usual on the Pi5) ⏳ ... Bu you will get an answer:
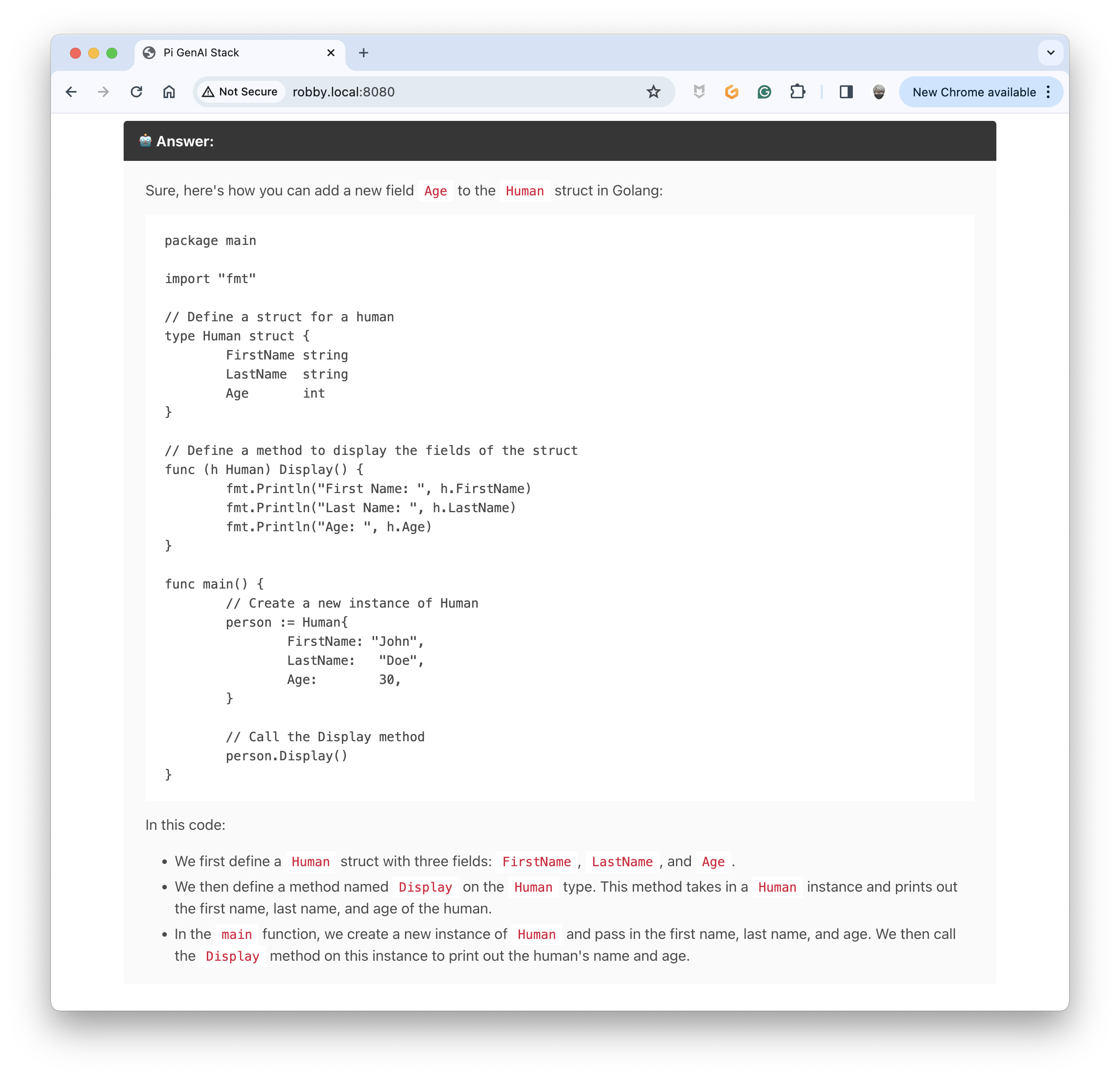
The Chatbot updated the source code correctly using the history of the messages 🎉. This is pretty cool 🥰.
👋 Consider having a way to reset the memory for when you want to change the topic of the conversation.
I used the
deepseek-coderLLM, the instruct version (deepseek-coder:instruct) should be more appropriate.
Well, that's all for today. My following experiments will revolve around RAG, something oriented towards documentation and source code. I am also trying to transform my ChatBot into a VSCode extension. Stay tuned.
you can find the source code of this blog post here: https://github.com/bots-garden/pi-genai-stack/tree/main/js-dev-environment/workspace/samples/06-prompt-memory-spa
✋ For a more advanced version of this example, have a look at this project: https://github.com/bots-garden/my-little-code-teacher