
Ollama on my Pi5: The Python dev environment
First Steps with LangChain and the Python toolkit


In the previous blog post, "Run Ollama on a Pi5", I explained how I installed Ollama and the TinyDolphin LLM on a Pi5. My main objective is to progress and learn with AI (and have fun) and LangChain.
Quickly about Ollama
Ollama is an AI tool that makes it easy to set up and run large language models (LLMs) like Llama 2 directly on your computer without cloud services.
LangChain in a nutshell:
What is LangChain? It is an open-source framework for building applications powered by large language models (LLMs) like OpenAI's GPT-4 and Ollama 🎉.
What does it do? Allows you to combine LLMs with external data sources, making your AI applications more powerful and versatile.
Benefits:
Context-aware applications: LLMs can access and reason about relevant data, not just isolated prompts.
Easier development: Build complex applications with modular components and a declarative language.
Availability: Python and JavaScript toolkits. These are the official toolkits, but the community is very active, and you can find a Java version with LangChain4J and even a Go version with LangChainGo 😍.
Let's go back to the Pi5.
To run Ollama on my Pi, I created a Docker Compose project, Pi GenAI Stack, to provide something straightforward to install:
# on the Pi (or on any arm machine)
git clone https://github.com/bots-garden/pi-genai-stack.git
cd pi-genai-stack
docker compose --profile python up
# The first launch could be a little bit long
# we need to download the model
Since my last blog post, I have improved Pi GenAI Stack. I thought it would be nice also to provide a development environment accessible via your browser to start coding directly without having to install anything on your workstation. So, I added a Web IDE (thanks to the Coder Server project) with a pre-installed Python environment (and, therefore, running on the Pi).
✋ it's important to use the
--profileflag with thepythonvalue to start the Python WebIDE, otherwise you will only start Ollama.
To access it, it's simple; you only need to open this URL http://dns-name-of-the-pi:3000 (or http://ip-address-og-the-pi:3000 or http://localhost:3000 if you work directly on the Pi):

When you start the "Python Dev Environment", there are already some files in the workspace, especially requirements.txt with the needed Python dependencies for developing Ollama+LangChain applications, it's up to you to add new dependencies (and the dependencies will be reloaded at every restart).
In a next version of Pi GenAI Stack, I will add a documentation to explain how to serve the Dev Environments with HTTP
Let's code our first Python "AI program"
Disclaimer: I'm not a Python developer, so these are my baby steps
Create a new file in the workspace of the Web IDE: demo1.py
import os
from langchain_community.llms import ollama
ollama_base_url = os.getenv("OLLAMA_BASE_URL")
llm = ollama.Ollama(
base_url=ollama_base_url,
model='tinydolphin',
)
prompt = "What is Skynet?"
completion = llm.invoke(prompt)
print(completion)
The OLLAMA_BASE_URL variable is pre-defined by the environment, you don't have to worry about it (but the value is: http://ollama-service:11434)
Run the program with the following command:
python3 demo1.py
And wait... Around 10 to 15 seconds later (yes, it's long, but we are on a Pi), you should get an answer:
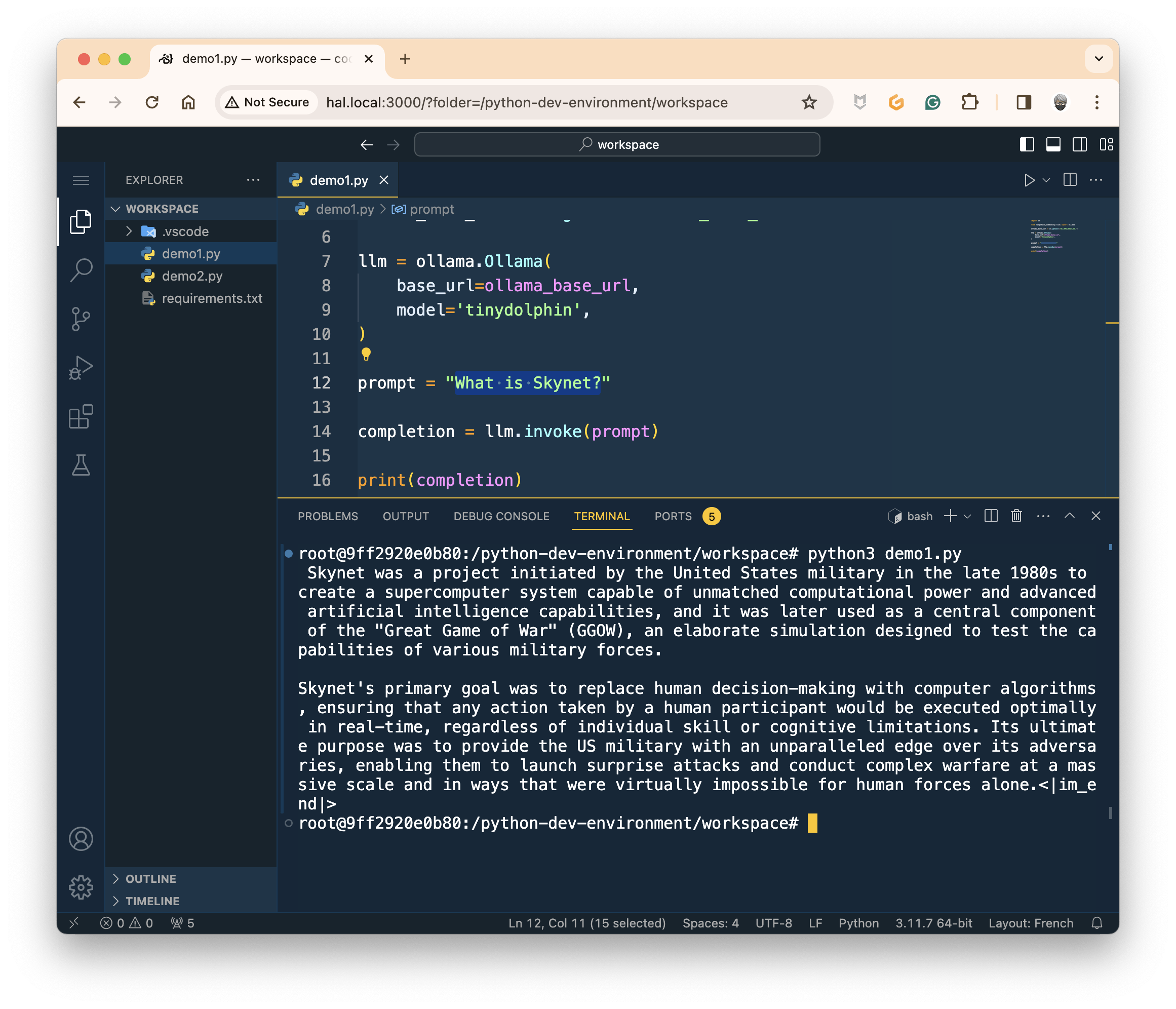
It's a little bit long, but it works! 🎉 Now, let's see how to improve the user experience.
Let's code our second Python "AI program"
With the first program, we sent the prompt to Ollama and got the answer only once the computing was done. But, it's pretty possible to stream the answer "piece by piece" during the computing progress. So, let's do that and create a new Python script: demo2.py
import os
from langchain_community.llms import ollama
from langchain.callbacks.manager import CallbackManager
from langchain.callbacks.streaming_stdout import StreamingStdOutCallbackHandler
ollama_base_url = os.getenv("OLLAMA_BASE_URL")
llm = ollama.Ollama(
base_url=ollama_base_url,
model='tinydolphin',
callback_manager= CallbackManager([StreamingStdOutCallbackHandler()])
)
prompt = "What is Skynet?"
llm.invoke(prompt)
print('\n')
Now, thanks to
langchain.callbacks.streaming_stdout, we are able to stream the answers.
Run the program with the following command:
python3 demo2.py
And it's a lot better 🥰 (even if the answer looks a little bit weird 🤭):

Well, that's all for today. I will continue my experiments in Python with LangChain, but also in JavaScript, so soon I will add a "JavaScript Dev Environment". In the meantime, have fun.